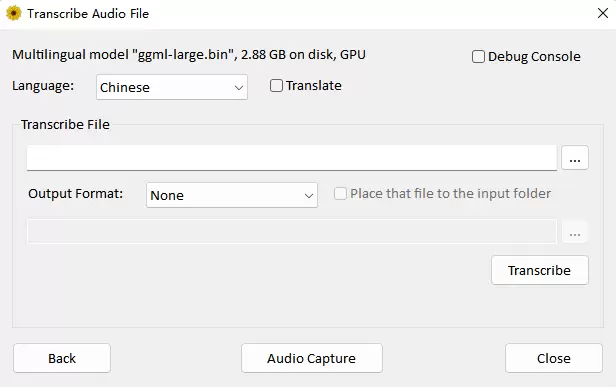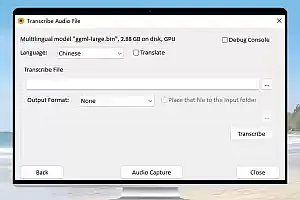
Whisper自动语音识别模型是一款强大的开源工具,可以将任意语言语音转换成文字。本文提供ggml-medium 语音模型,GPU和CPU版本Whisper
特点:
- 基于DirectCompute的厂商无关GPGPU技术,采用了Direct3D 11中的计算着色器。
- 纯C++实现,无需除操作系统组件外的其他运行时依赖。
- 与OpenAI实现相比,速度更快。在一台搭载GeForce 1080Ti GPU的桌面电脑上,使用中等模型对3分24秒的语音进行识别,使用PyTorch和CUDA需要45秒,而使用Whisper和DirectCompute只需19秒。有趣的是,Whisper仅需要431KB的运行时依赖,而OpenAI的实现需要9.63GB。
- 混合F16/F32精度:Windows需要D3D版本10.0以上支持R16_FLOAT缓冲区。
- 内置性能分析器,可测量各个计算着色器的执行时间。
- 内存使用低。
- 使用Media Foundation处理音频,支持大多数音频和视频格式,并支持大多数在Windows上工作的音频捕获设备(除了一些只实现ASIO API的专业设备)。
- 包含音频捕获的语音活动检测功能,基于Mohammad Moattar和Mahdi Homayoonpoor于2009年发表的文章《一种简单但高效的实时语音活动检测算法》。
- 提供易于使用的COM风格API,还提供了C#的包装器。
- 预构建的二进制可执行文件可用。
性能说明:
不同的GPU上进行了测试,以下是测试结果的简要总结:
- NVIDIA GeForce 1080Ti:相对速度为5.8(大型模型)和10.6(小型模型)。
- NVIDIA GeForce 2080Ti:相对速度为9.4(大型模型)和17.2(小型模型)。
- NVIDIA GeForce 3070:相对速度为9.7(大型模型)和17.7(小型模型)。
结论:
Whisper是一个令人印象深刻的高性能GPGPU推理引擎,为OpenAI的Whisper自动语音识别模型提供了快速而有效的推理能力。它的速度优势和低内存占用使其成为处理大规模语音数据的理想选择。如果您对自动语音识别技术感兴趣,不妨尝试使用Whisper来提升您的语音识别应用程序的性能和效率。
软件截图